
在当今的互联网时代,微博作为中国最受欢迎的社交媒体之一,已经成为许多人获取热点信息和洞察公众舆论的重要平台。无论是营销人员、研究者还是企业,都希望能够通过抓取微博数据,进行用户行为分析、市场调查以及舆情监测。如何高效地抓取这些数据并进行分析,常常是一个技术门槛较高的任务。
1.为什么需要抓取微博?
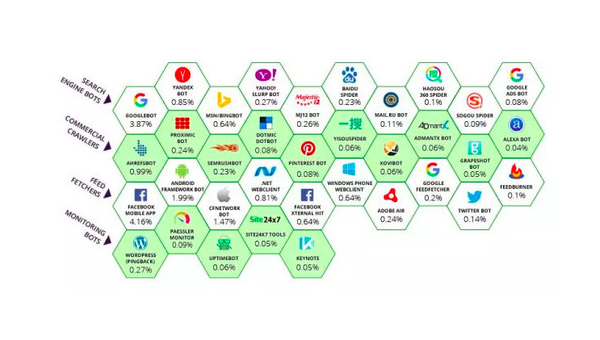
微博的内容丰富多样,涉及到新闻热点、娱乐事件、公众舆论、个人动态等多方面内容。抓取微博数据有以下几个关键好处:
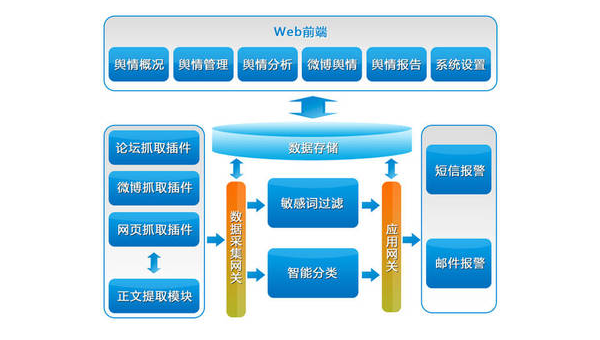
实时舆情监测:通过抓取实时微博数据,企业或政府可以第一时间了解公众舆论的动向,及时采取应对措施。
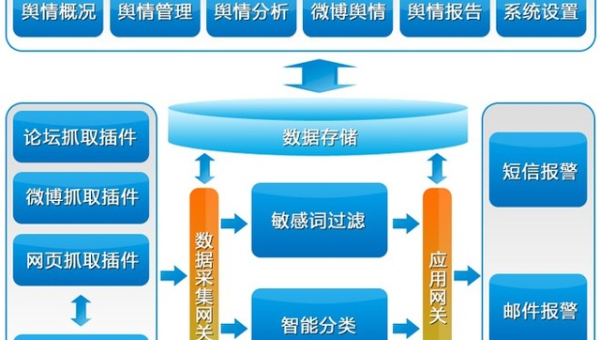
市场洞察:对营销人员来说,分析微博上的热点话题和用户评论,可以帮助其更好地了解消费者需求,制定精准的市场策略。
竞品分析:抓取竞争对手的微博内容,了解其品牌营销策略、用户反馈等信息,有助于企业进行竞争分析。
研究分析:对于学术研究者来说,微博数据是研究社会行为、用户情感、流行趋势等的重要素材。
2.微博抓取的基础原理
抓取微博的核心技术是“网络爬虫”,即通过模拟用户浏览器行为自动访问网页并提取页面中的数据。微博抓取通常分为两种方式:公开数据抓取和API抓取。
公开数据抓取:这种方式通常使用Python等编程语言,通过网络爬虫(如Scrapy、BeautifulSoup等)访问微博的网页,提取特定微博的内容,比如博文、评论、转发等。这种方法比较灵活,但微博对非授权的频繁访问有一定的防护机制(如反爬虫机制),需要应对封禁IP和验证码问题。
API抓取:微博官方提供了API接口,开发者可以通过申请微博开发者账号获取API权限,进而通过API访问微博数据。API抓取更加稳定,并且可以规避一些反爬虫机制,但有数据访问的额度限制,且部分API接口收费或权限较高。
3.开始抓取微博的准备工作
在开始微博数据抓取之前,需要做一些必要的准备工作:
编程环境搭建:大部分微博抓取工作都是通过编程语言来实现的,推荐使用Python语言,因为其拥有丰富的网络爬虫框架(如Scrapy)和数据处理库(如Pandas)。可以通过Anaconda或者PyCharm等工具搭建Python开发环境。
浏览器模拟与请求:为了更好地模拟真实用户访问微博页面,需要使用一些专门的库来处理HTTP请求,比如requests库。使用Selenium可以有效模拟浏览器行为,应对动态加载的数据。
防封策略:微博拥有较强的反爬虫机制,如频繁访问会导致IP被封禁、遇到验证码等。为应对这些问题,可以采取代理IP轮换、限制请求频率等措施。
4.微博抓取的具体实现
我们介绍微博抓取的具体步骤,以便您能够轻松上手。
1)使用API抓取数据
如果你想通过官方的微博API进行数据抓取,首先需要申请微博开发者账号,并创建一个应用来获取API访问密钥。申请流程相对简单,关键步骤如下:
注册成为微博开发者;
创建一个应用,获取API的AppKey和AppSecret;
根据微博提供的API文档,选择合适的接口,比如获取微博用户的信息、最新的微博动态、话题数据等。
通过微博API可以抓取到的内容包括用户信息、关注者列表、粉丝数、微博发布的内容、评论、转发等。调用API的典型代码如下:
importrequests
url='https://api.weibo.com/2/statuses/public_timeline.json'
params={
'access_token':'你的access_token',
'count':10
}
response=requests.get(url,params=params)
data=response.json()
print(data)
通过这种方式,你可以轻松获取到最新的微博内容并进行数据分析。
2)通过爬虫抓取公开数据
另一种方法是使用爬虫抓取微博的公开页面内容。下面是一个简单的Python爬虫实例,它可以抓取某个特定话题下的微博:
importrequests
frombs4importBeautifulSoup
headers={
'User-Agent':'你的浏览器UA'
}
#访问某个微博话题的搜索结果页面
url='https://s.weibo.com/weibo?q=特定话题'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.text,'html.parser')
#抓取微博内容
foriteminsoup.find_all('div',class_='content'):
print(item.get_text())
这里我们使用了BeautifulSoup库来解析网页内容,找到特定HTML元素中的微博数据,并将其提取出来。需要注意的是,微博页面采用了动态加载技术,所以需要结合Selenium等工具处理一些复杂的页面抓取。
5.数据存储与分析
抓取到微博数据后,可以将其存储在本地的CSV文件、数据库(如MySQL、MongoDB)中,方便后续的数据处理与分析。常用的数据分析方法包括:
情感分析:通过自然语言处理技术分析微博评论或内容中的情感倾向,判断用户的情绪。
词频分析:提取微博内容中的高频关键词,分析话题热点和趋势。
用户行为分析:通过分析用户的转发、点赞、评论行为,挖掘潜在的用户兴趣和需求。
6.总结
抓取微博数据是进行舆情监测、市场研究、用户行为分析等工作的关键步骤。通过使用微博API或网络爬虫技术,结合科学的数据存储与分析手段,能够帮助企业、研究者实现高效的信息采集和深度分析。在实际操作中,灵活应对反爬虫机制、合理设计抓取策略,是成功抓取微博数据的关键。
