
引言:微博评论为何重要?
在当前的数字时代,微博作为中国最大的社交媒体平台之一,汇集了大量用户的实时讨论和观点。无论是企业市场调研,学术研究,还是热点分析,微博评论都是极具价值的数据源。许多人想要从微博中获取评论数据,但不知道从何下手。本文将为你详细介绍如何通过爬虫技术轻松爬取微博评论,即使你是技术小白,也能顺利掌握这项技能。
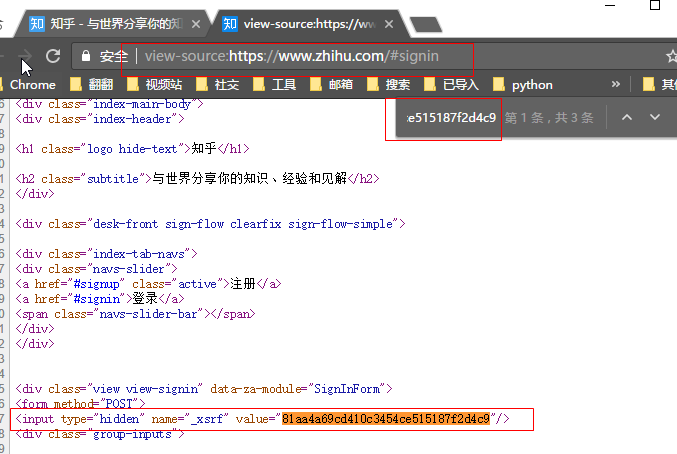
第一步:选择合适的工具和技术
在谈到爬取微博评论时,我们首先需要考虑的就是选择合适的工具。一般来说,最常用的编程语言是Python,因为它拥有丰富的爬虫库,易于上手。
Python:作为最流行的编程语言之一,Python以其简单易懂的语法和强大的第三方库被广泛应用于网络爬虫开发。对于初学者,Python是一个非常好的选择。
常用爬虫库:Python中最常用的爬虫库包括Requests、BeautifulSoup和Scrapy。其中,Requests用于发送HTTP请求,BeautifulSoup用于解析网页数据,而Scrapy是一个功能强大的框架,可以帮助你构建高效的爬虫程序。
微博API:微博官方提供了一些API接口,允许用户通过授权的方式获取微博数据。不过,API获取的数据有一定的限制,因此很多人选择通过模拟网页抓取的方式直接爬取评论。

第二步:了解微博反爬机制
在实际操作中,微博评论的爬取并不总是那么顺利。微博拥有比较完善的反爬虫机制,旨在防止未经授权的爬取行为。常见的反爬策略包括IP封禁、验证码验证、请求频率限制等。因此,我们需要采取一些有效的应对策略:
频率控制:通过在爬虫程序中加入时间延迟,避免短时间内发送大量请求。通常使用time.sleep()函数来模拟人工的浏览行为。
代理IP:通过使用代理IP池来动态更换IP地址,以避免被微博封禁。市面上有许多代理IP服务提供商,可以为爬虫提供大量的可用IP。
模拟浏览器行为:爬虫可以使用类似Selenium这样的工具来模拟真实用户的浏览器行为,包括页面滚动、点击、等待加载等,增加爬虫的隐蔽性。
验证码处理:遇到验证码时,可以使用一些图像识别技术,比如tesseract,或者通过打码平台来实现自动化识别。
第三步:微博评论爬取的基本流程
分析目标页面:通过微博网页版找到你想要爬取评论的微博链接。通过浏览器的开发者工具,检查评论数据是如何加载的,通常评论会通过Ajax请求动态加载。
发送请求:使用Requests库发送HTTP请求,获取目标微博页面的HTML代码或评论数据的API接口返回的JSON数据。
解析数据:如果页面数据以HTML格式返回,可以使用BeautifulSoup库进行解析;如果是JSON数据,直接用Python的内置json模块处理。
数据存储:将爬取到的评论数据保存为CSV、JSON、数据库等常用格式,方便后续分析。
在第一部分中,我们了解了如何选择工具、面对反爬机制以及基本的爬取流程,接下来让我们继续深入探讨如何提高爬取效率,处理数据,确保数据的完整性和准确性。
第四步:优化爬虫效率
在大规模爬取数据时,效率是一个必须考虑的重要因素。特别是在爬取大量微博评论时,如果没有适当的优化策略,爬虫程序可能会变得非常缓慢,甚至导致IP封禁。因此,提升爬取效率的策略主要包括:
异步爬取:使用异步编程技术(如Python中的asyncio和aiohttp库),可以同时发送多个请求,从而极大提高爬取速度。与传统的同步爬虫不同,异步爬虫可以在等待网络响应时执行其他任务,最大限度地减少时间浪费。
多线程/多进程:通过多线程或多进程技术,爬虫程序可以并发处理多个任务。Python的threading和multiprocessing库可以帮助你快速实现这一点。
分布式爬虫:如果数据量非常大,可以考虑使用分布式爬虫架构。比如使用Scrapy-Redis框架,将爬取任务分配给多台服务器同时进行,这样可以有效应对大量数据爬取的需求。
第五步:处理和清洗数据
从微博爬取到的评论数据并不能直接用于分析,它们可能包含许多无用信息,比如HTML标签、表情符号、广告内容等。因此,数据清洗是必不可少的一步。以下是常见的清洗方法:
去除HTML标签:使用正则表达式或BeautifulSoup的get_text()方法去除评论中的HTML标签,保留纯文本内容。
去除噪音:通过关键词过滤或者基于规则的方法,去除广告、无意义字符和表情符号。Python的re库可以帮助进行复杂的文本匹配和替换。
去重:对重复的评论或用户回复进行去重处理,以确保数据的唯一性。可以通过对每条评论生成唯一的ID进行比较。
第六步:合法与合规性
爬取微博评论虽然技术上可行,但一定要注意合法与合规性。未经授权的大规模爬取数据可能违反微博的用户协议或相关法律法规。因此,建议:
尊重网站的robots.txt文件:该文件规定了网站允许或禁止爬虫访问的部分。尽量遵守这些规定,避免爬取敏感数据。
注意数据的使用权限:如果是进行商业用途的数据爬取,必须获取微博官方的授权,确保不会侵犯用户隐私或数据所有权。
总结:从零到一的微博评论爬取
通过本文的介绍,你应该已经掌握了如何从零开始爬取微博评论的基础知识和技术细节。从选择工具到处理反爬机制,再到优化爬虫效率和数据清洗,每一步都有其关键点。如果你是初学者,建议从基础入手,逐步实践;而对于有一定经验的开发者,可以尝试异步编程或分布式爬虫来提升效率。
不论是出于研究目的,还是数据分析需求,掌握微博评论爬取技术将为你提供无限的可能性。希望这篇教程能够帮助你在数据获取的道路上少走弯路,快速上手!
